📚 Study Material: Compiler Design - Lexical Analysis and Parsing
Source Information: This study material has been compiled from a lecture audio transcript and copy-pasted text provided by the user.
🚀 Introduction to Compiler Design: Lexical Analysis and Parsing
This study material provides an overview of two fundamental phases in compiler design: lexical analysis and parsing. We will explore the challenges associated with naive approaches, the simplification techniques employed, and the core concepts behind different parsing strategies. Understanding these concepts is crucial for comprehending how programming languages are processed and translated into executable code.
1. 🔍 Lexical Analysis: Tokenizing the Input
Lexical analysis, also known as scanning, is the first phase of a compiler. Its primary role is to read the source code character by character and group them into meaningful units called "tokens."
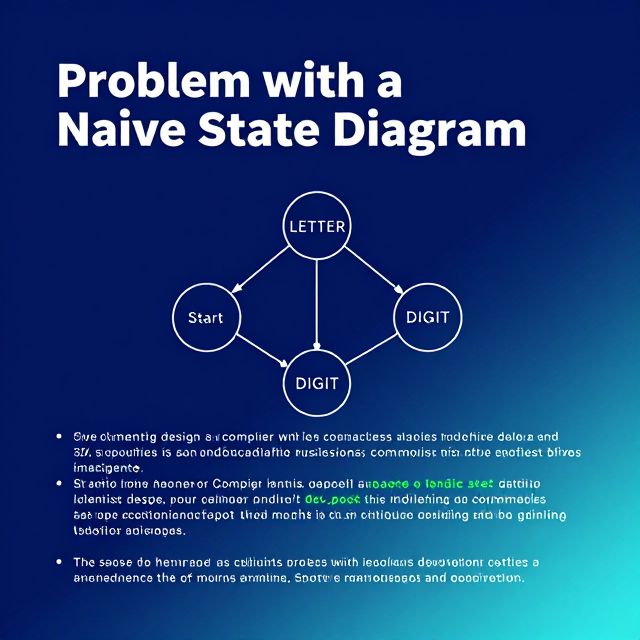
1.1. The Problem with Naive State Diagrams ⚠️
Programming languages contain a vast array of characters: letters (A-Z, a-z), digits (0-9), operators (+, -, =, etc.), and punctuation symbols (!, ?, :, etc.). If a state diagram for a lexical analyzer were to include a transition for every possible character from every state, it would become:
- Very complex: An overwhelming number of transitions.
- Difficult to design: Managing such complexity is impractical.
- Hard to maintain: Changes would be extremely challenging.
1.2. Motivation for Simplification ✅
To overcome the complexity of naive state diagrams, lexical analyzer design employs simplification techniques:
- Character Classes: Grouping similar characters together.
- Shared Transitions: Using a single transition for a group of characters.
- Table-Driven Implementations: Using tables to represent state transitions, making the design more compact.
These techniques ensure the state diagram remains compact and manageable.
1.3. Character Classes in Detail 💡
Character classes significantly reduce the number of transitions.
- Identifiers: Instead of
Start -> a,Start -> b, ...,Start -> Z, we defineLETTER = {A-Z, a-z}. The diagram then simplifies toStart -> LETTER. - Integer Literals: Similarly, for digits, we define
DIGIT = {0-9}instead of individual transitions for each digit.
Using character classes:
- Reduces the number of transitions.
- Simplifies design and improves readability.
- Enhances maintainability of the scanner.
1.4. Handling Reserved Words and Identifiers 📚
Many programming languages have reserved words (e.g., if, while, return) and identifiers (e.g., sum, value, count) that share the same lexical pattern (strings of letters and possibly digits).
- The lexical analyzer can recognize both using the same part of the state diagram.
- This avoids creating separate states or transitions for every reserved word, preventing unnecessary diagram enlargement.
1.5. Convenient Utility Subprograms 🛠️
Lexical analyzer implementations often use helper functions:
getChar():- Reads the next character from the input source program.
- Stores it in a variable (e.g.,
nextChar). - Determines its character class (e.g.,
LETTER,DIGIT,UNKNOWNfor operators/punctuation) and stores it (e.g.,charClass).
addChar():- Adds the
nextCharto the lexeme being constructed (e.g., in a string calledlexeme). - Example: For "total", it builds
t -> to -> tot -> tota -> total.
- Adds the
Lookup():- Checks if the completed
lexemeis a reserved word or special symbol. - If it is, returns the corresponding token (e.g.,
if->IF,+->ADD_OP). - If not, it's typically classified as a general identifier token (
IDENT).
- Checks if the completed
2. 🌳 The Parsing Problem: Structuring the Code
Parsing, or syntax analysis, is the second phase of a compiler. It takes the stream of tokens from the lexical analyzer and checks if they conform to the language's grammar rules.
2.1. Main Objectives of a Parser 🎯
- Syntax Checking:
- Verifies if the token sequence follows the grammar rules.
- If a violation occurs, it must:
- Detect the syntax error.
- Produce a clear diagnostic error message (e.g., "Syntax error: unexpected operator + in assignment expression for
X =+ 5"). - Recover quickly to continue analyzing the rest of the program, allowing multiple errors to be reported in one compilation.
- Parse Tree Construction:
- If the program is syntactically correct, the parser builds a parse tree (or information to construct it).
- A parse tree represents the hierarchical structure of the program according to the grammar rules.
2.2. Parser Categories 📊
Parsers are generally divided into two main categories based on how they construct the parse tree:
- Top-Down Parsers: Build the parse tree from the root downwards to the leaves.
- Bottom-Up Parsers: Build the parse tree from the leaves upwards to the root.
Most practical parsers look ahead only one token in the input stream to make parsing decisions, balancing efficiency and practicality.
3. ⬇️ Top-Down Parsers: From Root to Leaves
Top-down parsers construct the parse tree starting from the root (the start symbol of the grammar) and expanding towards the leaves (the input tokens). This process follows a leftmost derivation.
3.1. Parsing Decision 🧐
At each step, the parser considers a sentential form xAα (where x is processed terminals, A is the leftmost nonterminal to expand, and α is the remaining string).
- The key challenge is deciding which grammar rule to apply for nonterminal
A. - This decision is typically made by examining the lookahead token (
t). The parser chooses the rule forAwhose right-hand side can generatetas its first symbol.
3.2. Common Top-Down Parsing Algorithms ⚙️
- Recursive-Descent Parsing:
- Implemented as a set of recursive functions, one for each nonterminal.
- Each function corresponds to a grammar rule.
- The parser calls these functions to expand nonterminals (e.g.,
Expr()callsTerm(), which callsFactor()).
- LL Parsers (Table-Driven):
- Use a parsing table instead of explicit recursive code.
- The table determines which grammar rule to apply based on the current nonterminal and the next input token.
- LL stands for:
- First
L: Scans input from Left to right. - Second
L: Constructs a Leftmost derivation.
- First
3.3. The Problem of Left Recursion ⚠️
Top-down parsers cannot handle left-recursive grammars.
- A grammar is left-recursive if there exists a nonterminal
Asuch thatAcan derive a string starting withAitself (i.e.,A + Aα). - This leads to non-termination in a top-down parser, as it would endlessly try to expand
Awith itself. - Any recursion in a top-down parser must be right recursion.
3.4. Eliminating Left Recursion 🔄
Left recursion must be eliminated by transforming the grammar.
- General Transformation: For a grammar fragment
A Aα | β(where neitherαnorβstart withA), it can be rewritten as:A β A'A' α A' | ε(whereA'is a new nonterminal andεis the empty string).
- This transformation converts left recursion into right recursion, defining the same language.
- Example:
- Original:
Expr Expr + Term | Term - Transformed:
Expr Term Expr',Expr' + Term Expr' | ε
- Original:
3.5. Predictive Parsing and LL(1) Property 🧠
Predictive parsing is a top-down technique that aims to choose the correct grammar rule without backtracking.
- FIRST Sets: For a production
A α,FIRST(α)is the set of terminal symbols that can appear as the first symbol in any string derived fromα. - LL(1) Property: A grammar has the LL(1) property if, for any two alternative productions for a nonterminal
A αandA β, theirFIRSTsets are disjoint:FIRST(α) ∩ FIRST(β) = ∅. This allows the parser to make a correct decision with just one lookahead symbol. - Epsilon Productions and FOLLOW Sets: If
ε(empty string) is inFIRST(α), thenFOLLOW(A)must also be considered.FOLLOW(A)is the set of terminal symbols that can immediately followAin a sentential form.FIRST+(Aα)is defined asFIRST(α) ∪ FOLLOW(A)ifε FIRST(α), otherwiseFIRST(α).- A grammar is LL(1) if for
A αandA β,FIRST+(Aα) ∩ FIRST+(Aβ) = ∅.
4. ⬆️ Bottom-Up Parsers: From Leaves to Root
Bottom-up parsers construct the parse tree starting from the leaves (input tokens) and gradually work upwards toward the root (the start symbol). This process corresponds to the reverse of a rightmost derivation.
4.1. The Reduction Process 🧩
- Instead of predicting grammar rules, bottom-up parsers combine tokens and smaller structures into larger constructs.
- At any step, the parser examines a "right sentential form" (a string of terminals and nonterminals).
- It identifies a substring that matches the right-hand side (RHS) of a grammar rule.
- This substring is then reduced to the corresponding left-hand side (LHS) of the rule.
- This reduction process continues until the entire input is reduced to the grammar's start symbol, forming the root of the parse tree.







